Navigating Julia's autodiff ecosystem
(Based loosely on a talk I gave in a lab meeting)
Julia has a great autodiff ecosystem. Unfortunately, it isn’t documented very well.
For example, this page is the first result when I google “julia autodiff”. It’s pretty unhelpful. It gives a long list of packages, but no indication about which ones are most commonly used or actively maintained.
I’ll provide a sketch of (i) which packages are actually useful, (ii) their most useful features, and (iii) how they relate to each other.
Big picture
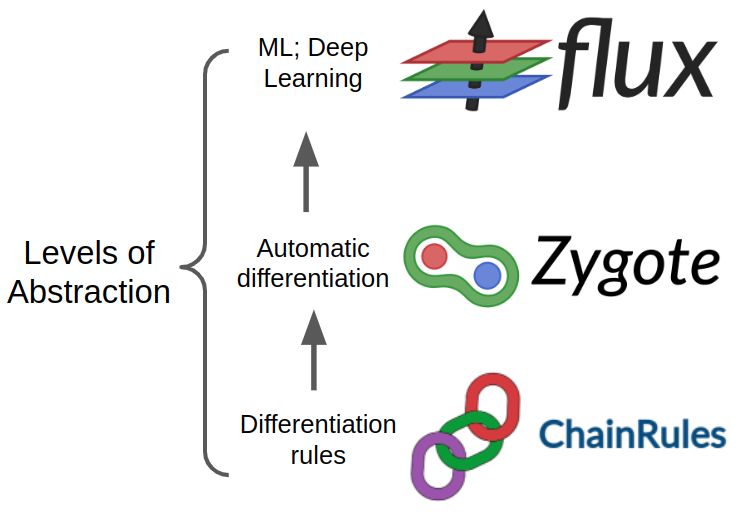
The most prominent, mature, and widely used autodiff packages form an ecosystem with different packages covering different levels of abstraction:
- ChainRules.jl provides an interface for defining backpropagation rules on your functions.
- Zygote.jl stitches these rules together to carry out backpropagation and compute gradients on composed functions (i.e., computational DAGs).
- Flux.jl provides some machinery for building and training machine learning models on top of Zygote.jl.
I’ll provide some helpful details about each of these.
ChainRules.jl
Suppose you have an exciting new operation, and you want to include it as a layer in your neural network.
There’s a decent chance that Zygote will be able to differentiate it without any additional work from you—Zygote can differentiate a large fragment of the Julia language as-is.
However, in the event that Zygote fails to differentiate your operation (or does so inefficiently), ChainRules provides an interface for defining your very own custom chain rule for it.
There are two (interconnected) steps to writing a chain rule:
- Write a
pullbackfunction- This defines backpropagation for your operation.
- It receives the “error” in the operation’s output, and returns the “error” in the operation’s input. (The precise mathematical terminology becomes cumbersome).
- Implement the
rrulefunction for your operation- This function (i) performs the forward-mode computation of your operation and (ii) lays the groundwork for backpropagation.
- It receives (i) the operation and (ii) the operation inputs as arguments.
- It returns (i) the operation outputs and (ii) the
pullbackfunction. Most often, thepullbackfunction is defined in the body of yourrruleimplementation. This allows useful intermediate quantities to be reused during backpropagation.
This may seem convoluted—it took some thinking and reading to wrap my brain around it.
You get the hang of it after a couple of times, though.
In fact, I’ve come to think that rrules and pullbacks are kind of the “correct” abstraction for backpropagation.
Once you’ve implemented these functions, Zygote will be able to autodiff your operation wherever it appears in a computational DAG. Gone are the days of trying to shoehorn your research idea into the PyTorch or TensorFlow API.
Zygote.jl
Once each operation in your computational DAG is differentiable, you can use Zygote to perform autodifferentiation.
The interface is very simple. Suppose your_dag is a callable, differentiable computational graph. Then Zygote’s gradient function will return a tuple of gradients:
grads = Zygote.gradient(your_dag, arg1, arg2, ..., argN)
Alternatively, the withgradient function returns the function value and the gradients.
val, grads = Zygote.withgradient(your_dag, arg1, arg2, ..., argN)
This is useful for, e.g., returning the loss and the gradient simultaneously when training a neural net.
Flux.jl
Flux is the most widely used deep learning package in the Julia ecosystem. It’s built on top of Zygote and ChainRules (both of which seem stable and well-designed).
However, Flux is still an immature package in some surprising ways:
- Its machinery for (i) collecting model parameters and (ii) applying updates to them has issues that seem fundamental.
- See this GitHub issue for discussion. Chris Rackauckas is one of the most prominent developers and users of Flux (and Julia more generally). His perspective carries weight.
- Flux’s documentation is unhelpful.
- For example, the issue about model parameters mentioned above is not discussed anywhere in the documentation. I only got information about it after hours of confused searches through source code, GitHub issues, and forum discussions.
- The documentation reuses the same overly-simple example to illustrate different parts of the API—this leaves a lot of uncertainty about correct usage.
That said, there are still features in Flux that I find useful:
- Movement between CPU and GPU. Flux has some machinery that makes it very easy to move your model and data from CPU to GPU (and back).
- Optimizers. Flux has implementations of some popular stochastic gradient-based optimization procedures: ADADelta, ADAM, AMSGrad, etc.
These features alone make Flux worthwhile.
Parting words
For an example usage of the Julia autodiff ecosystem, feel free to look at my MatFac.jl package.
In the Python world, I’m also excited about the autodiff ecosystem growing up around JAX.
I suspect Julia has advantages over JAX, though. Julia’s extensibility via ChainRules is a major strength. Another strength is that Julia makes no distinction between fast, differentiable tensor operations and the base language. Contrast this with JAX (and every other Python-based deep learning framework), which uses Python to “glue together” the fast, compiled code.
\( \blacksquare\)